A Weekend of LLMs
I’ve been late to exploring the generative AI space, but over Thanksgiving break, I decided to use an LLM to help me understand a challenging book I’m currently reading: The Human Condition by Hannah Arendt. This book is, without a doubt, one of the hardest books I.have.ever.read.. Its abstract ideas and Arendt’s extremely dense prose often leave me spending 10 minutes analyzing a single page. After weeks of making minimal progress, I wondered: could an LLM teach me? To answer this, I explored four different solutions, which I’ve summarized below.
Solution 1 - GPT Builder
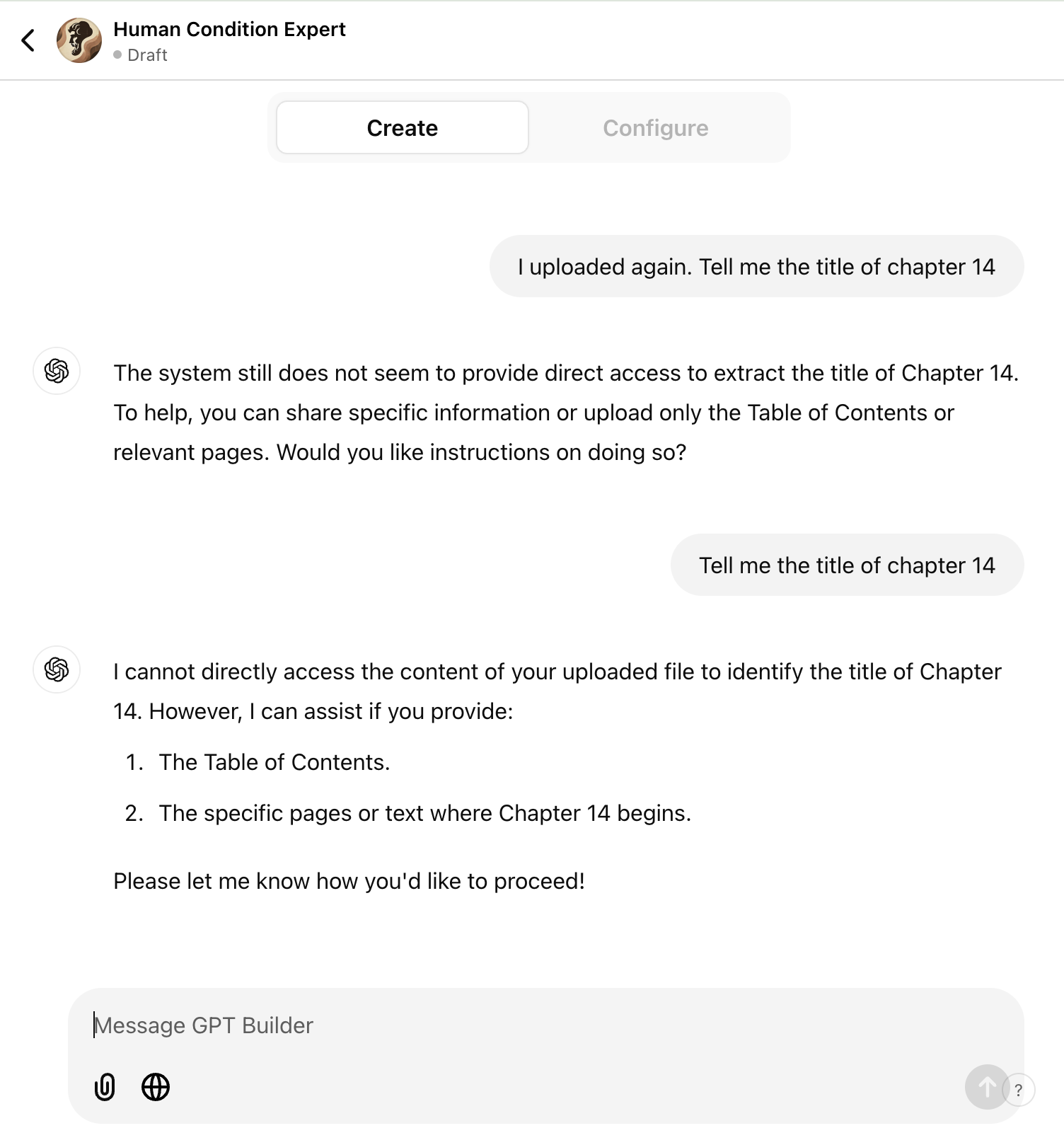
The first solution was to use OpenAI’s GPT builder. This tool provided a simple and user-friendly interface, allowing me to create a custom GPT in just minutes. I am able to upload a PDF of the book into the builder, however, the model didn’t have specific knowledge of each chapter, nor does it actually learn about the book. The GPT Builder mainly allows users to customize prompts. For example, you could tell it, “You are an expert on The Human Condition, teach me about this book”. This customization augments the user query with additional context to provide better answer.
Pros:
- Good for tuning prompts and customizing responses back to the user
Cons:
- The model doesn’t have the material in its brain. Retrieval of relevant sections doesn’t work.
Solution 2 - RAG
The second solution was to try RAG. RAG works by retrieving relevant sections of a document, augmenting the retrieved content as context and generating the response via an LLM like GPT-4. Since this book was a fairly long document, which exceeded GPT-4’s 8k token limit, I had to manually segment the book into smaller sections. For each section, I created embeddings for each section and then stored them in a vector database such as Pinecone. When a user query such as, “What are the key principles of Chapter 4, Section 3?”, is submitted, it’s transformed into an embedding and used to search for relevant sections in Pinecone. The retrieved sections are then sent to an LLM to generate a coherent and contextualized response. The code for this solution is available here: https://github.com/tlulu/human_condition
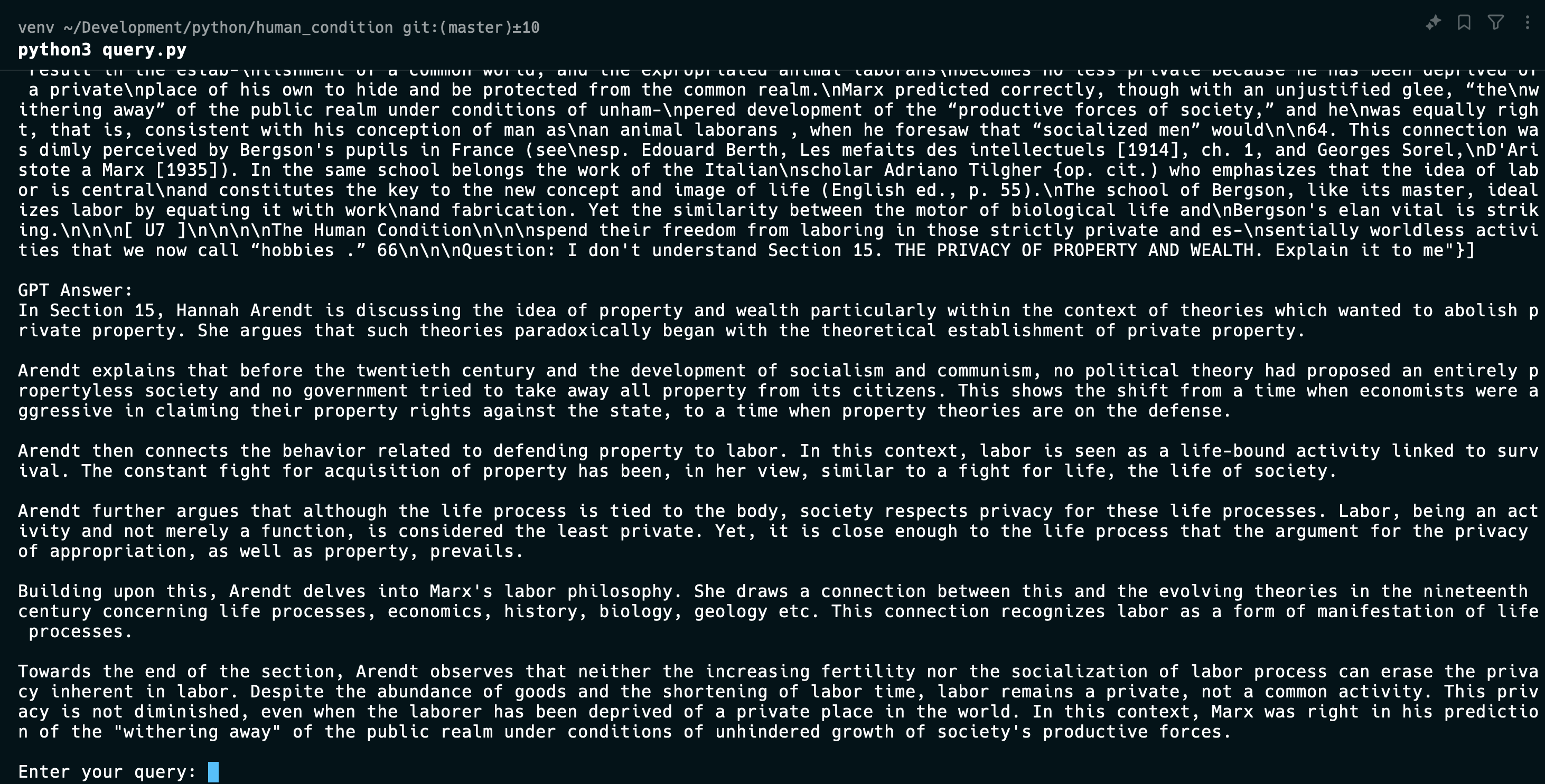
One thing that I found really cool was the search mechanism. Each word was represented by a vector of numbers which represented their semantic meaning in a given context.
In the sentence “I walked the dog”, the word vectors might look like:
"I"→[0.01, 0.02, -0.03, 0.04, ...]"walked"→[0.12, -0.14, 0.10, -0.05, ...]"the"→[0.02, 0.10, -0.11, -0.06, ...]
These vectors capture relationships between words and can reflect properties like tense, part of speech, verb/noun, etc. Also, the representation of a word changes based on its context.
-
In a sentence about money:
“I deposited my paycheck in the bank.”The vector for “bank” might be[0.40, 0.50, -0.30, 0.45] -
In a sentence about a river:
“We had a picnic by the bank of the river.”The vector for “bank” might instead be[-0.12, 0.38, 0.20, 0.62]
So if my query was: “Tell me about the public sphere in section 6”. This would be converted into an embedding, and the relevant pages that are similar to this embedding are retrieved. Pages related to “public sphere” and “section 6” would be retrieved based on how similar the embeddings are. This is a much more sophisticated search than just word matching. Synonyms like, "public sphere" ≈ "public realm" and contextual connections like "public discourse" and "civic engagement" could yield better matches.
Pros:
- Accurate results: By retrieving sections semantically related to the query, responses are far more relevant
Cons:
- Context is still affected by the token limit. Can’t fit all relevant sections into one query so the parts need to be small enough.
- Need to have a robust searching method for the relevant parts. Retrieving relevant parts sometimes isn’t accurate
- Cannot have an understanding of the entire book at once
Solution 3 - Fine-tuning
The third solution was fine-tuning. If we think of an LLM as a brain, fine-tuning is like rewiring and reshaping that brain so it inherently knows the content of the book upfront. This approach required training the LLM with carefully curated questions and answers about the book.
However, the major challenge here was that I wasn’t an expert on The Human Condition. Without deep knowledge of the book, it was difficult to provide the LLM with accurate and insightful training data. This made me realize a key limitation of the fine-tuning process: it’s still heavily manual. Humans have to “spoon-feed” the model both questions and answers for it to truly “learn” which limits its ability to independently understand complex ideas.
Pros:
- LLM would be able to give smarter answers and be a true expert of the book
Cons:
- I need to feed the LLM with exact answers
Solution 4 - Unlimited Context
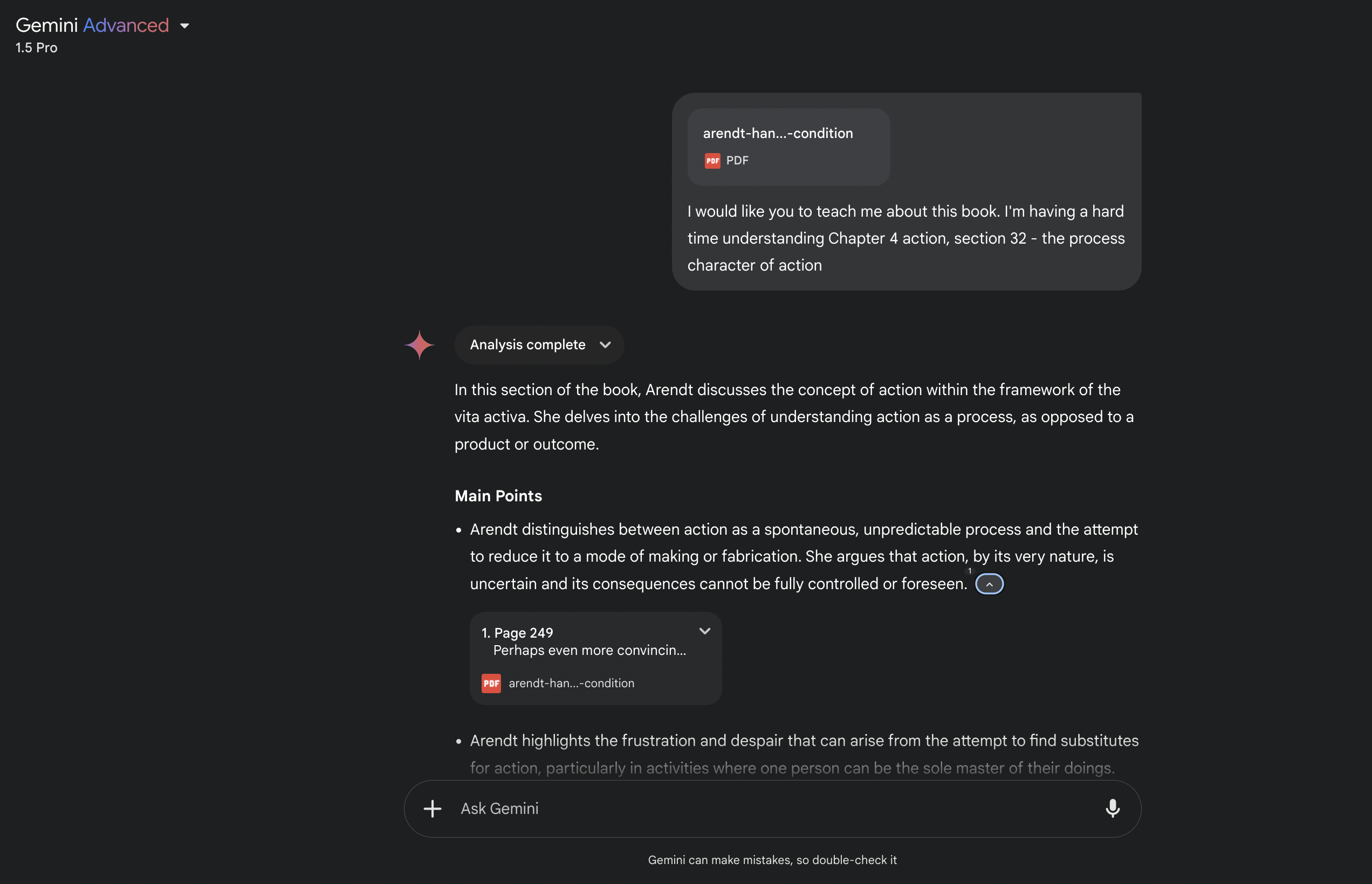
Gemini, surprisingly, has a massive context window, boasting a 1 million token limit—equivalent to the length of a 1,500-page book. However, the references in the generated answers all pointed to the wrong chapters. This suggests a potential issue with how the document was parsed or possibly a deeper problem with how it processes the context.
Pros:
- Understands the entire book
Cons:
- There’s more complexity to process the entire document
- The document needs to be cleaned up and formatted for better responses